HW2之2 <<
Previous Next >> 同學的問題集中串
HW2之3
由於我的知識淺薄所以還沒有辦法使用python完全地將名單給呈現出來只能用稍微不那麼手動的辦法弄出來,所以接下來的答案絕對不是正確解答


以上為我想的到的解決方法,如果已經知道誰的學號和帳號不一樣並確認帳號了話,那就直接建立字典把少數的學號跟帳號給拉出來分別定義,雖然這甚至比自己手動輸入還慢但至少...是用程式去跑的
如下圖:
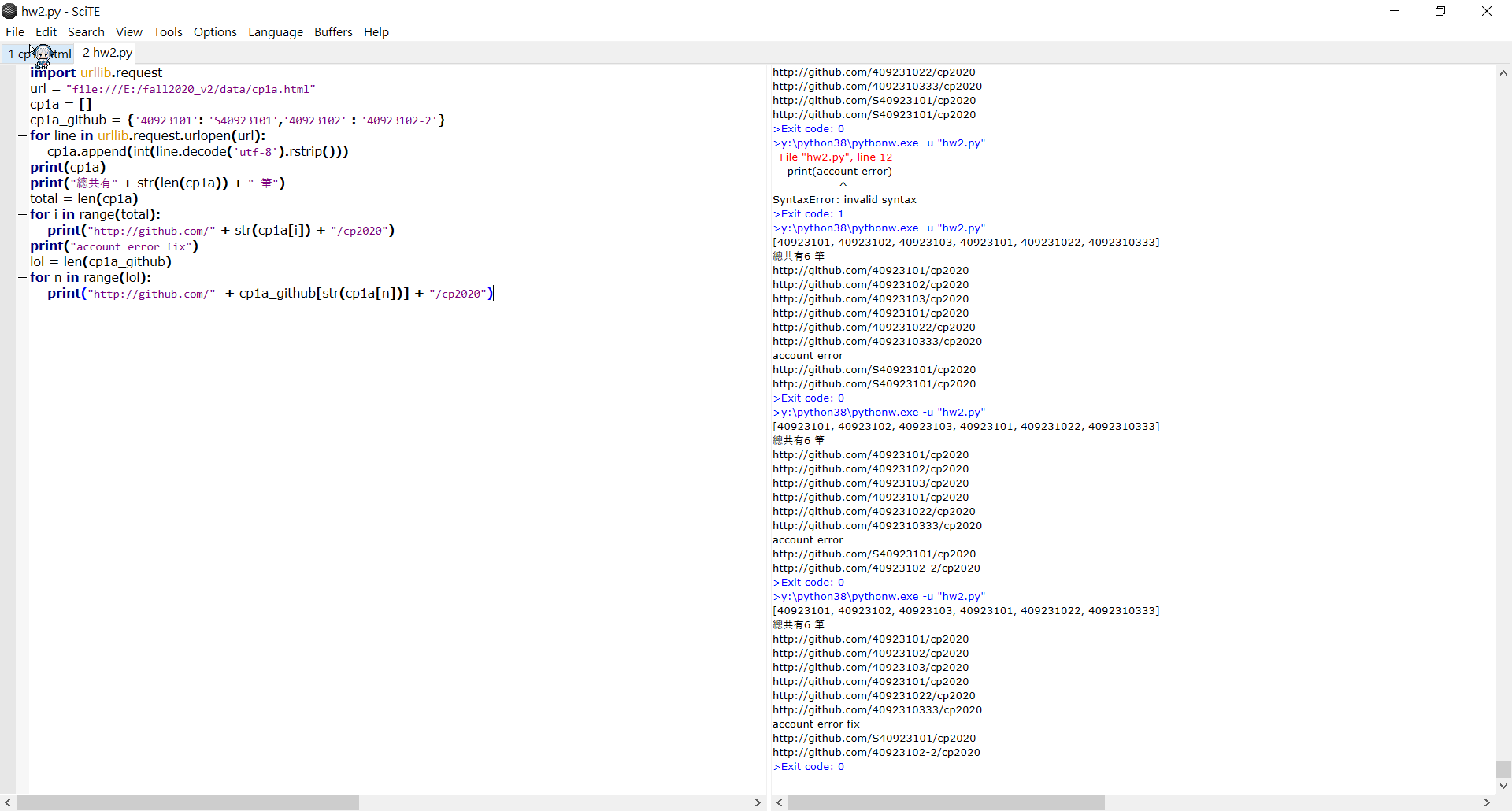
- 首先我先建立名單的超連結檔並將其設定成源頭,並做出假設如果學號40923101和40923102的帳號分別是S40923101以及40923102-2為前提下
- 並新增字典cp1a_github = {'40923101': 'S40923101','40923102' : '40923102-2'}將這兩個不一樣的分別拉出來
- 然後在所有名單出來之後增加帳號錯誤修正的字串
- 然後用迴圈去跑字典裡的字串並顯示出來
總結
由於在測試時上述的line.decode('utf-8').rstrip()貌似只能讀懂數字,其他的如中文 英文 標點符號 甚至空白都會讀不出來
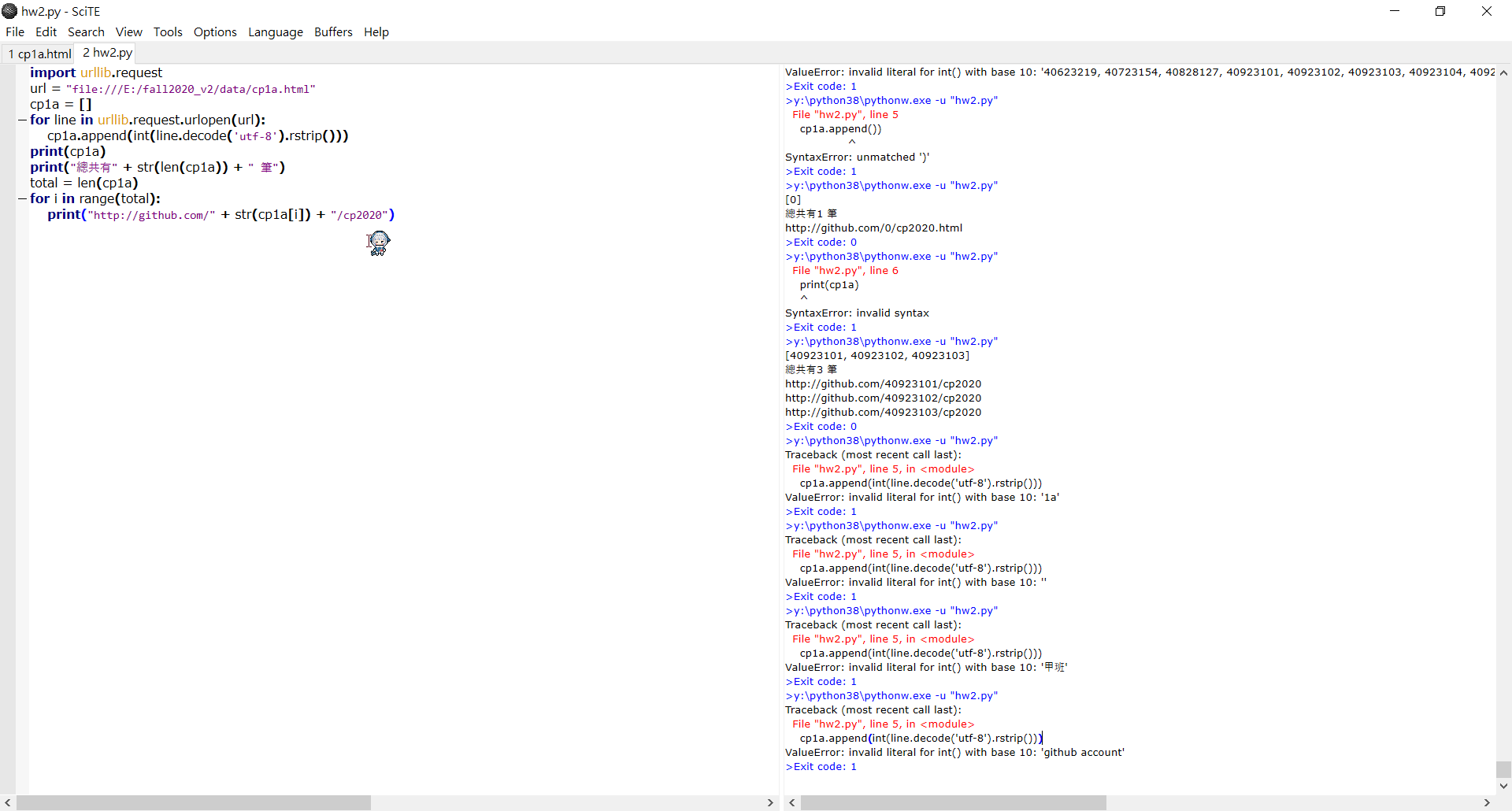
所以這個方法算是在避免更動原程式狀況下的其中一種方法
最後是我自己的解答
import urllib.request
url = "file:///E:/fall2020_v2/data/cp1a.html"
cp1a = []
cp1a_github = {'40923101': 'S40923101','40923102' : '40923102-2'}
for line in urllib.request.urlopen(url):
cp1a.append(int(line.decode('utf-8').rstrip()))
print(cp1a)
print("總共有" + str(len(cp1a)) + " 筆")
total = len(cp1a)
for i in range(total):
print("http://github.com/" + str(cp1a[i]) + "/cp2020")
print("account error fix")
lol = len(cp1a_github)
for n in range(lol):
print("http://github.com/" + cp1a_github[str(cp1a[n])] + "/cp2020")
下圖是改編前的程式
import urllib.request
url = "https://nfulist.herokuapp.com/?semester=1091&courseno=0762"
cp1a = []
for line in urllib.request.urlopen(url):
cp1a.append(int(line.decode('utf-8').rstrip()))
print(cp1a)
print("總共有" + str(len(cp1a)) + " 筆")
total = len(cp1a)
for i in range(total):
print("http://github.com/" + str(cp1a[i]) + "/cp2020")
最後收穫的知識有
- urllib.request能讀得好像不只是http連file都可以'
- 迴圈的使用方法
- dict的使用方法
HW2之2 <<
Previous Next >> 同學的問題集中串